今天又是美好的一天,Skylar 一如往常地躺在沙發上,滑著手機。但是,他有點看膩了追蹤帳號的內容,他跳到 explore 頁面,想看看有沒有什麼新的帳號和內容可以追蹤。Instagram 是怎麼知道要推薦什麼給用戶呢?我們今天一起來研究其中的奧秘吧!
閱讀之前的溫馨小提醒:本文會提到一些機器學習的名詞,例如 word2vec、embedding、KNN 模型等等。由於篇幅關係,無法一一詳盡說明,可以先記在心中,等閱讀完本文後再參考其他說明(私心推薦李宏毅老師的機器學習課程,講解深入淺出,很好理解)。
Instgram 主要分成三個區塊
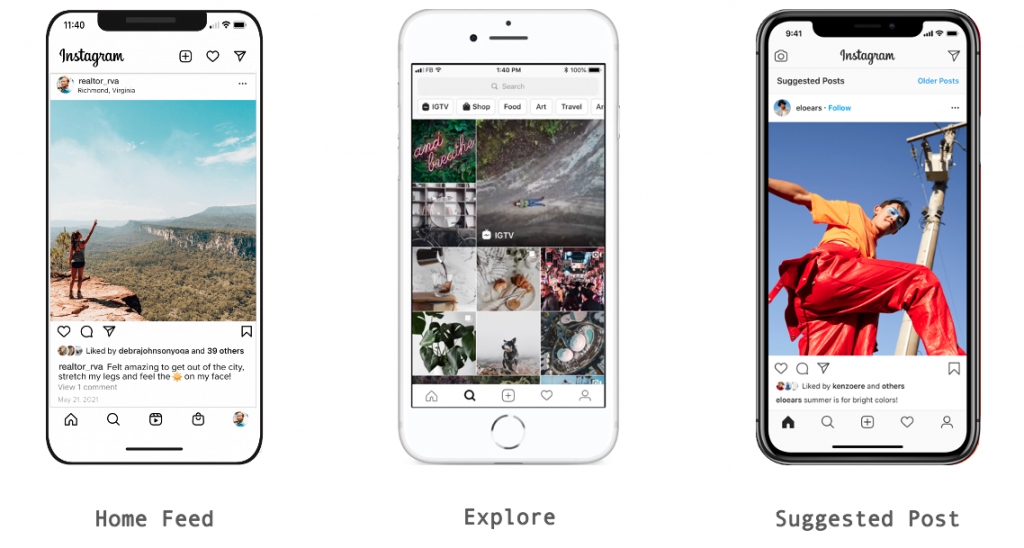
今天先聊聊第二種 Explore Ranking System 的介紹,Suggested Post 則會在之後說明。
本次內容分為兩大部分:
在深入探討之前,先來點數字感受一下 Instagram 的推薦系統有多厲害:在每一秒鐘可以擷取六百五十億個 feeatures,並產生九千萬個模型預測結果。很了不起吧!讓我們來看看究竟是設計什麼樣的方式,才可以如此有效率地開發。
為了以下幾個痛點,Instagram 開發三個工具,分別對應如下:
IGQL 是 Instagram 自己獨創的語言,和 Python 一樣好上手,又像 C++ 一樣執行起來有效率且省資源。
優點是易讀、易學、易提取需要的資料,不會耗費大量資源,且 query 可稍加修改就令做它途。
範例如下所示:
user
.let(seed_id=user_id)
.liked(max_num_to_retrieve=30)
.account_nn(embedding_config=default)
.posted_media(max_media_per_account=10)
.filter(non_recommendable_model_threshold=0.2)
.rank(ranking_model=default)
.diversify_by(seed_id, method=round_robin)
想到要推薦內容時,最直覺地的想法是觀察每個用戶喜歡的內容,再推薦相似的主題給他。例如 Skylar 喜歡攝影、美食和太空,可以直接推薦關於這三個主題的帳號給他。然而,我們無法將 Skylar 這個帳號歸納在單一主題。不能說他是攝影帳號,因為他也會發美食和太空的文。同理,也不能說他是專門的美食或太空帳號。
用戶的興趣太廣,不容易使用 media-level 的 embeddings 來推薦內容。因此,與其按照貼文本身的主題推薦 Skylar,不如直接推薦和 Skylar 相似的帳號。
這就是所謂 account-level 的資訊,而 Instagram 使用 account embedding 擷取特徵,以判斷哪些帳號比較相似。
計算 account embedding的方法是 ig2vec -- 一種類似於 word2vec 的概念。因為篇幅關係,本文將不贅述 word2vec 的詳細原理,有興趣的人可以找尋相關內容。總之,Ig2vec 將用戶互動的過程視為句子中每個字的序列。
利用和 word2vec 的同樣概念,能夠預測用戶下一個時間點比較可能能會和哪些帳號互動。互動行為包含按讚、分享、留言,以及儲存貼文等等。

若能夠預測每個用戶的互動行為,便可知道哪些用戶在拓墣上較為相似。換句話說,藉由判斷用戶的 account embedding 在向量空間中是否相近,以確認是否為相似帳號。兩個帳號之間距離計算方式通常使用 cosine distance 或向量內積,並利用 KNN 模型尋找鄰近的相似帳號,最後使用 Facebook 的 FAISS 模型提取資料。
利用 account embedding 查找相似的帳號,能夠幫助我們用更有效率、簡單的方式縮小可能的推薦內容清單。
最後,為了確保在向量空間中距離相近的帳號,真的內容相似。Instagram 訓練一個能夠根據 embedding、預測帳號主題的分類器,再將預測結果和人工判斷的主題比對,以驗證正確性。
目的:節省資源、更快速輕量地選取 candidates。
由於每秒鐘要處理的帳號太多,Instagram 會在使用更複雜的排序模型之前,先選擇一些帳號放入候選清單。並訓練一個極為輕量的模型,使用較少的特徵及較簡單的類神經網絡訓練,試圖複製較複雜模型的結果。
至於實際模型的使用過程,我們會在下篇解釋。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下訂閱,才不會錯過最新更新,也可以按讚給我鼓勵唷!
並歡迎到我的 medium 逛逛!
Reference


 iThome鐵人賽
iThome鐵人賽